
The Transformer Model: Revolutionizing Natural Language Processing #
Keywords: transformer model, natural language processing, NLP, machine learning, artificial intelligence, deep learning
In the world of artificial intelligence and natural language processing, few innovations have made as significant an impact as the transformer model. This groundbreaking architecture has revolutionized how machines understand and generate human language. Let’s dive into the key components that make transformers so powerful.
The Building Blocks of a Transformer #
The transformer architecture consists of several crucial elements:
- Tokenization
- Embedding
- Positional encoding
- Transformer blocks (multiple)
- Softmax layer
Each of these components plays a vital role in the model’s ability to process and generate language. Let’s explore them in detail.
1. Tokenization: Breaking Language into Manageable Pieces #
Tokenization is the first step in processing text for a transformer model. It involves breaking down text into smaller units called tokens. These tokens can be words, subwords, or even individual characters, depending on the specific tokenization method used.

Different tokenization strategies can significantly impact a model’s performance and efficiency. For instance, subword tokenization allows models to handle rare words and different languages more effectively.
2. Embedding: Turning Words into Numbers #
Once text is tokenized, the next step is to convert these tokens into a format that machines can understand – numbers. This is where embedding comes in. Embedding turns each token into a vector of numbers, representing its meaning in a multi-dimensional space.
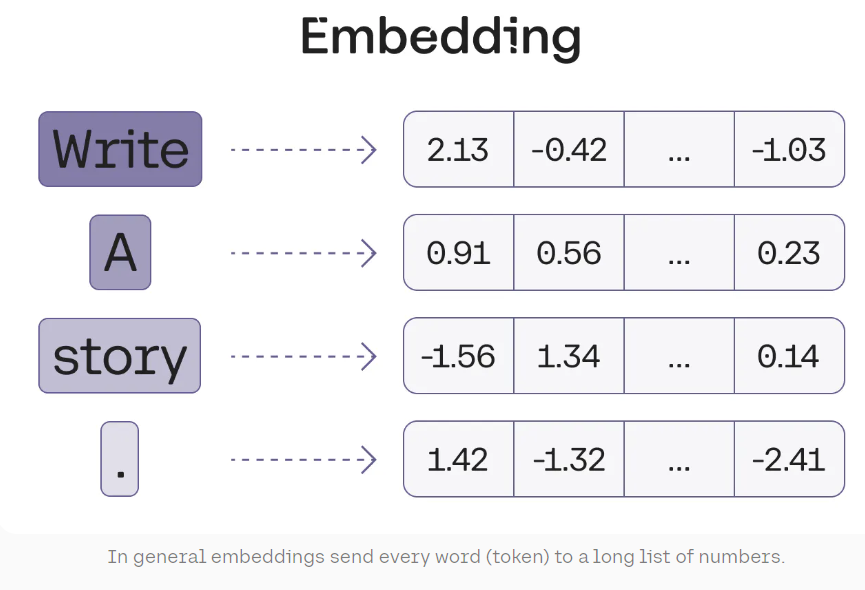
These embeddings capture semantic relationships between words, allowing the model to understand context and meaning. Different transformer models may use embeddings of varying dimensions, typically ranging from 128 to 1024 or more.
3. Positional Encoding: Preserving Word Order #
Unlike recurrent neural networks, transformer models process all words in a sentence simultaneously. This parallel processing is efficient but loses information about word order. Positional encoding solves this problem by adding information about a token’s position in the sequence to its embedding.
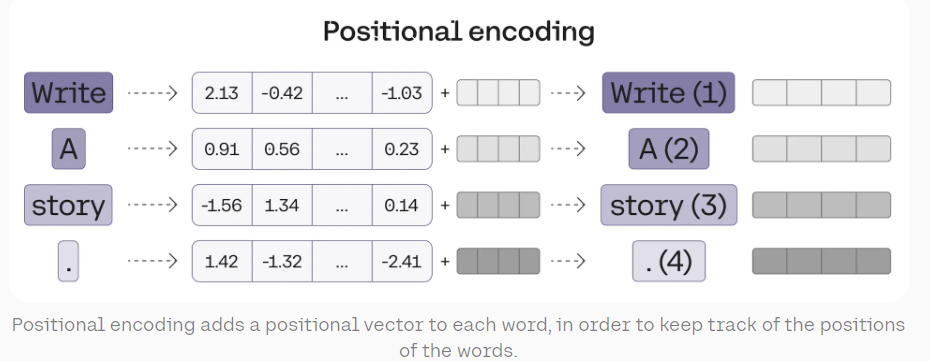
This clever technique ensures that the model can distinguish between sentences with the same words in different orders, preserving crucial syntactic information.
4. Transformer Blocks: The Heart of the Model #
The transformer block is where the magic happens. Each block consists of two main components:
- The attention mechanism
- The feedforward neural network
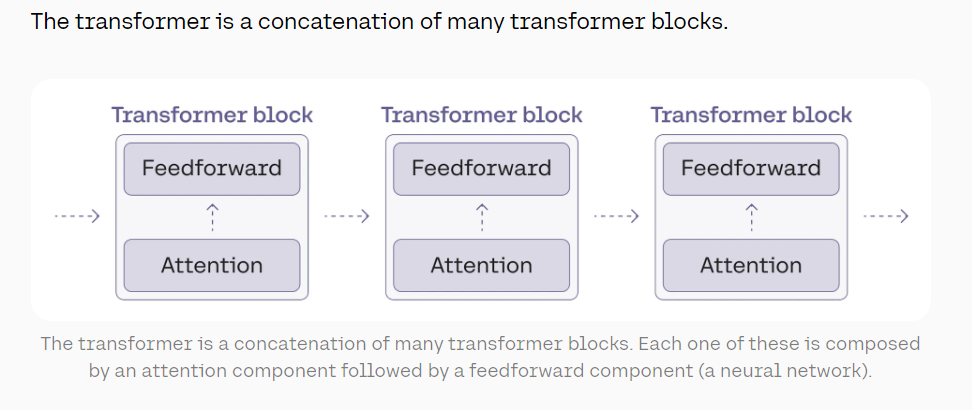
Multiple transformer blocks are typically stacked on top of each other, allowing the model to learn increasingly complex language patterns.
Attention: Understanding Context #
The attention mechanism is a key innovation in transformer models. It allows the model to focus on different parts of the input when processing each word, capturing context and relationships between words.
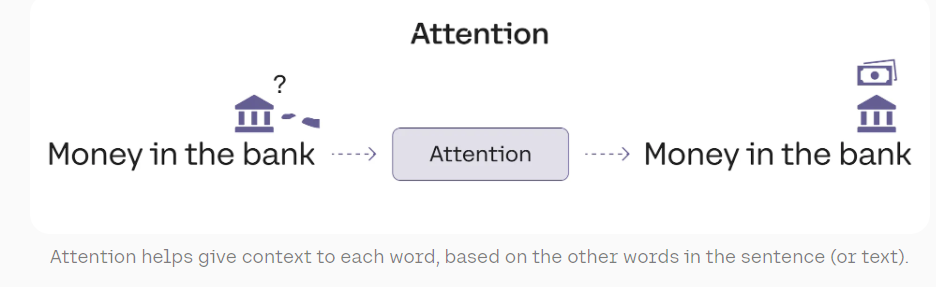
For example, in the sentences “The bank of the river” and “Money in the bank,” the attention mechanism helps the model understand the different meanings of “bank” based on context.
Transformers often use multi-head attention, where several different attention mechanisms operate in parallel, allowing the model to capture various types of relationships simultaneously.
5. The Softmax Layer: Generating Probabilities #
The final layer of a transformer model is typically a softmax layer. This layer takes the raw outputs from the transformer blocks and converts them into probabilities.
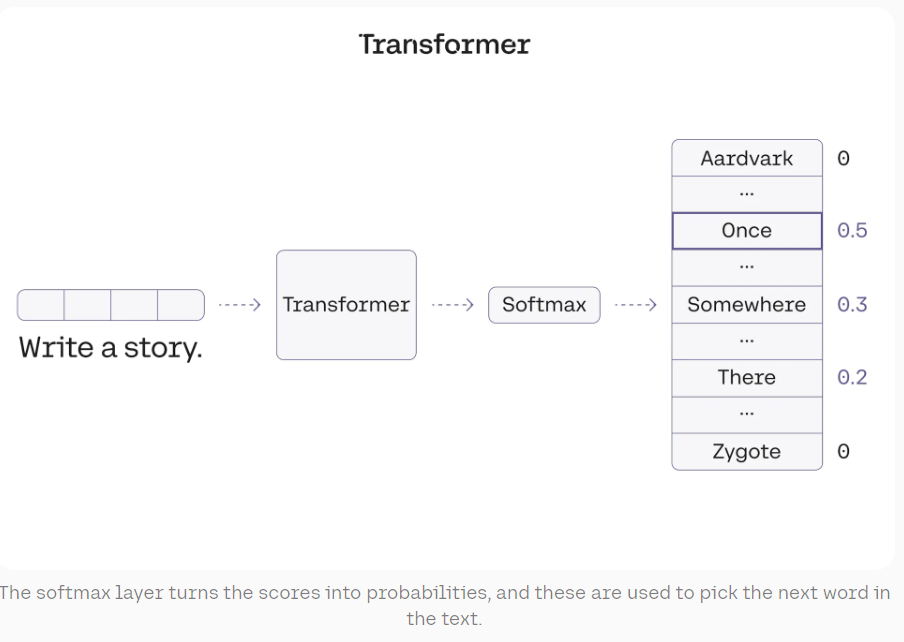
For tasks like language generation, these probabilities represent the likelihood of each word in the vocabulary being the next word in the sequence. The word with the highest probability is often chosen as the model’s output.
Beyond Training: Fine-Tuning and Adaptation #
While the basic architecture of transformer models is powerful, their true potential is realized through fine-tuning and adaptation. Post-training techniques allow these models to excel in specific tasks or domains.
For instance, a general-purpose transformer can be fine-tuned on conversational data to create a chatbot, or on code repositories to assist with programming tasks. This flexibility and adaptability have made transformers the backbone of many modern AI applications.
Conclusion: The Future of Language AI #
The transformer architecture has fundamentally changed the landscape of natural language processing. From machine translation to chatbots, from content generation to code completion, transformers are powering a new generation of AI capabilities.
As research continues and these models become more sophisticated, we can expect even more impressive applications in the future. The era of truly intelligent language AI is just beginning, and transformers are leading the way.